
DETR: End-to-End Object Detection with Transformers
DETR (DEtection TRansformer): Bipartite matching loss + Transformer
ECCV 2020 발표 논문
자연어 처리 분야에서 주로 사용되는 transformer를 적용한 object detection 방법을 제안한다.
Main Contribution
-
Object detection: direct set prediction
Object detection 문제를 direct set prediction 의 관점에서 해결하려고 했다. 딥러닝 네트워크의 prediction이 set형태로 나오는데, 여기서 set의 정의를 생각해보는게 중요하다. set은 순서에 상관없이, 중복되지 않은 요소들의 집합이라는 특성이 있다. 이후에도 언급될 내용이지만 prediction 결과들이 서로 중복되지 않도록 네트워크 단에서 학습이 되므로 기존 object detection 기법들에서 사용된 Non Maxima Supperssion, Anchor Generation 등의 prior knowledge (or hand-craft, heuristic method)를 배제하고 end-to-end 학습이 가능하다. 또한 prediction 결과들의 순서가 상관이 없다는 집합적 특성으로 인해 손실함수를 계산할 때 GT와 1대1 매칭을 시켜줄 biparite matching 기법이 사용된다.
기존 object detction 기법들에서 사용된 NMS, anchor generation 부분이 필요없이, end-to-end 학습이 가능하다는 점에서 의미가 있다.
-
Transformer
Self-attention 메커니즘을 통해 이미지의 local한 feature 외에도 이미지내의 local한 영역들이 각각 서로간에 갖고 있는 연관성을 학습한다.
-
Bipartite matching loss
이분 매칭 기법은 이 논문의 핵심 아이디어 중 하나로 set prediction 문제를 해결하기 위해 사용된다
Transformer
-
Transformer
Transformer는 Attention Is All You Need (NIPS 2017)에서 처음 제안되었고 자연어 처리 네트워크에서 핵심이 되는 기법이다.
Transformer는 주로 sequence 정보를 처리하는데 사용되어 왔는데, sequence(문장)의 각각 요소(단어)들로부터 정보를 모으는(aggregate) 기법이다.
그 중 이 논문에서 사용한 self-attention 기법은 sequence의 요소들이 각각에 대해서 서로 가지는 연관성에 대한 정보를 학습한다.
-
Attention
Attention을 위해 쿼리(Query), 키(Key), 값(Value)이 필요하다
Transformer에서는 이 Attention 과정을 여러 레이어에서 반복한다.
-
Self-attention
입력 문장(Sequence)에서 각 단어가 다른 어떤 단어와 연관성이 높은 지 계산한다.
-
Multi-head Attention
-
Positional Encoding
주기함수(sin, cos)를 활용한 공식을 사용하여 각 단어의 상대적인 위치 정보를 네트워크에 입력한다.
-
-
Transformer in DETR
Transformer를 적용하기 위해 DETR은 이미지 전체를 패치단위로 나누어 sequence 형태의 데이터로 변환하여 입력한다.
Attention을 통해 전체 이미지의 문맥 정보를 이해하고 이미지 내 각 인스턴스(로컬 패치)의 상호작용을 파악하기 용이하여 기존 CNN 기반의 object detecion 기법들과 달리 큰 bounding box에서의 거리가 먼 픽셀 간의 연관성을 파악할 수 있다.
-
Encoder
이미지 특징정보를 포함하고 있는 각 픽셀 위치 데이터를 입력받아 인코딩을 수행한다.
-
Decoder
N개의 object query를 초기 입력으로 받으며 인코딩된 정보를 활용한다.
각 object query는 이미지 내 서로 다른 고유한 인스턴스를 구별하도록 학습된다.
-
DETR Architecture
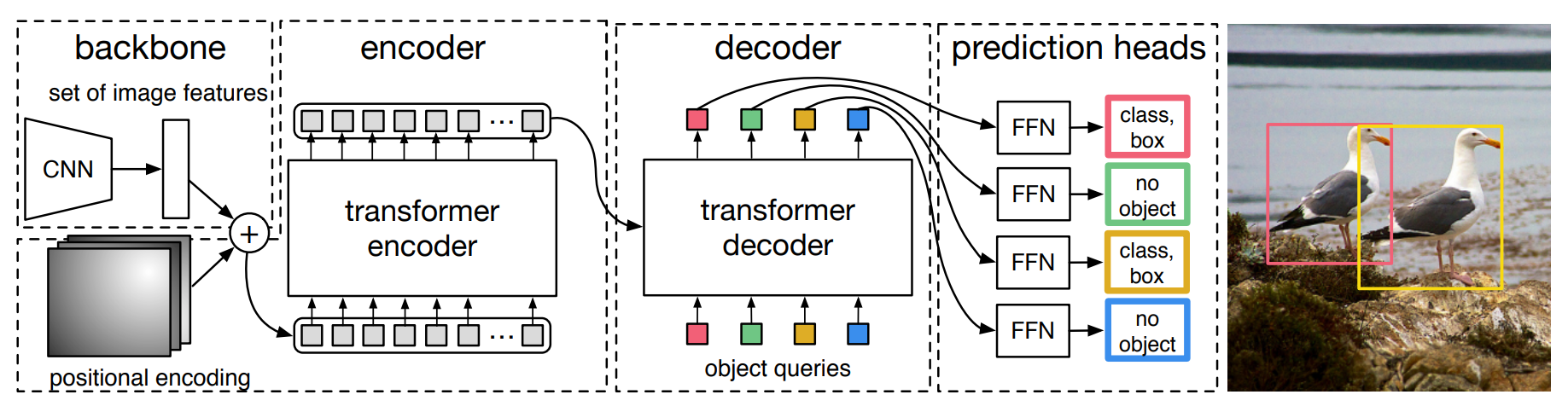
In Details
Decoder: 각 queries가 서로 중복되지 않는 방향으로 학습
Experiments
-
Dataset
COCO 2017 detection and panoptic segmentation datasets
118K training images
5K validation images
-
Comparable to Faster R-CNN
-
Lower performances on small objects
Implementation
- V100 GPU 16개 기준(각 GPU 마다 4장의 이미지 처리, 배치크기 64)으로 300 epoch 학습시키는 3일이 걸렸다.
Ablation Study
-
Encoder layer 수
-
Decoder layer 수
NMS effects
-
Importance of FFN
-
Importance of positional encodings
-
Loss ablations
이 논문은 Transformer를 활용하여 object detection 문제를 해결하기 위한 방법으로 object detection을 direct set prediction problem으로 해석하였다. image-to-set prediction을 수행하는 방식으로 접근하면서 Faster RCNN과 비교할 만 한 성능을 내어 transformer의 활용가능성을 입증했다는 점에서 의의를 갖는다. 다만 아직 작은 물체에 대한 성능이 비교적 낮은 점 등의 보완점이 있는데, 이후에 Deformable DETR 같은 후속 연구가 나타나면서 transformer를 활용한 object detection 성능 향상을 기대할 수 있게 되었다. 영상 인식에서 transformer를 적용하는 연구가 아직 초기단계라 CNN을 완전히 배제하지 못한 점이 아쉽지만 앞으로 더 많은 연구가 진행되어 hardware resource burden을 줄이면서 transformer를 잘 활용할 수 있게 된다면 기존 CNN을 이용한 기법들의 한계를 해결할 수 있을 것 같다는 기대감이 들었다.